Abstract
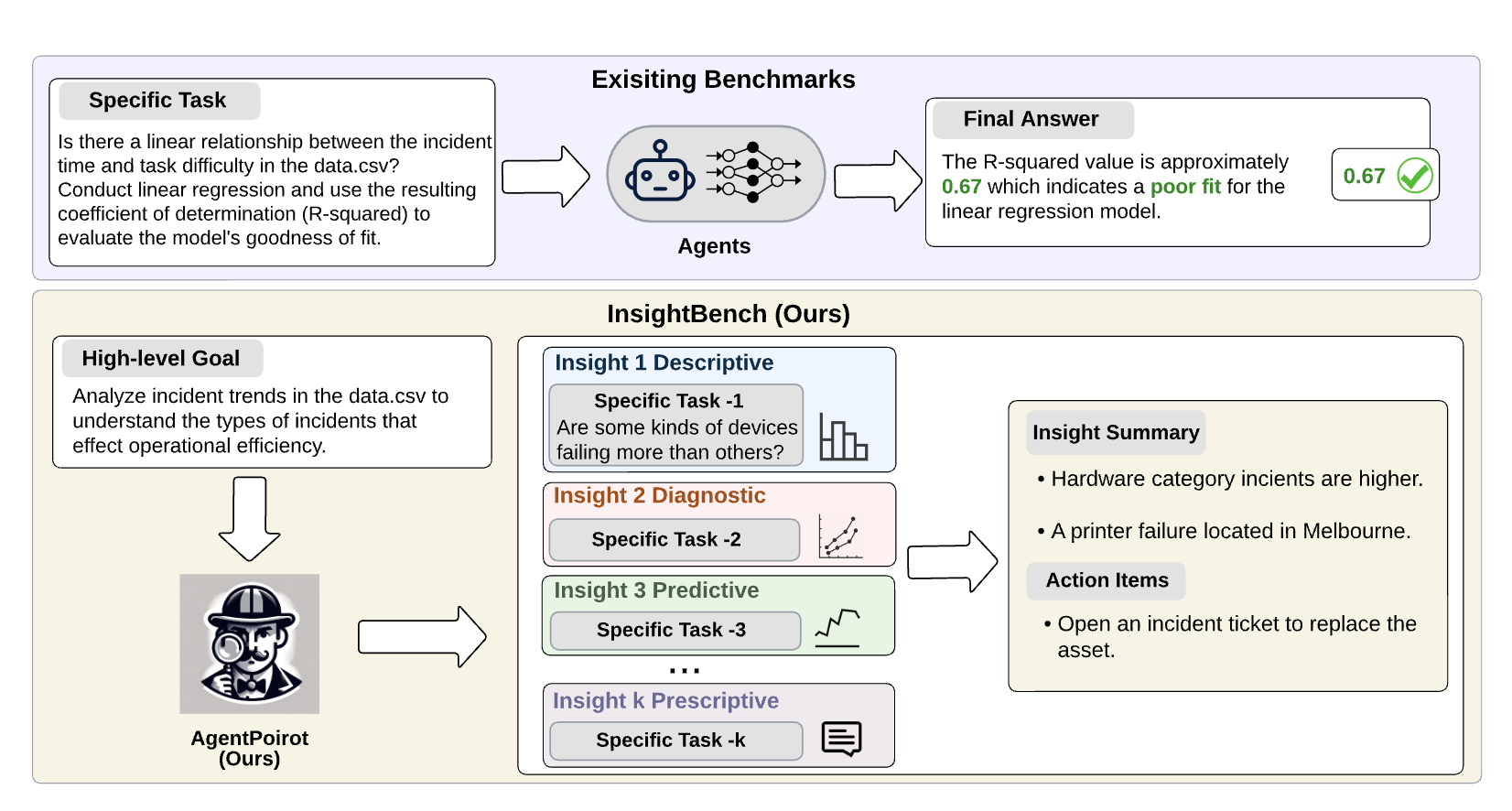
Data analytics is essential for extracting valuable insights from data that can assist organizations in making effective decisions. We introduce InsightBench, a benchmark dataset with three key features.
- InsightBench Introduction. InsightBench consists of 31 datasets representing diverse business use cases such as finance and incident management, each accompanied by a carefully curated set of insights planted in the datasets.
- End-to-End Analytics Evaluation. Unlike existing benchmarks focusing on answering single queries, InsightBench evaluates agents based on their ability to perform end-to-end data analytics, including formulating questions, interpreting answers, and generating a summary of insights and actionable steps.
- Quality Assurance. We conducted comprehensive quality assurance to ensure that each dataset in the benchmark had clear goals and included relevant and meaningful questions and analysis.
We have implemented a two-way evaluation mechanism utilizing LLaMA-3-Eval as an effective, open-source evaluator method for assessing agents' ability to extract insights. Additionally, we introduce AgentPoirot, our baseline data analysis agent capable of conducting end-to-end data analytics. Our evaluation on InsightBench demonstrates that AgentPoirot surpasses existing approaches, such as the Pandas Agent, which primarily focus on resolving single queries. We also conduct a comparison of the performance between open and closed-source LLMs, along with various evaluation strategies. In summary, this benchmark serves as a testbed to inspire further advancements in comprehensive data analytics. The benchmark repository can be accessed here:https://github.com/ServiceNow/insight-bench
AgentPoirot
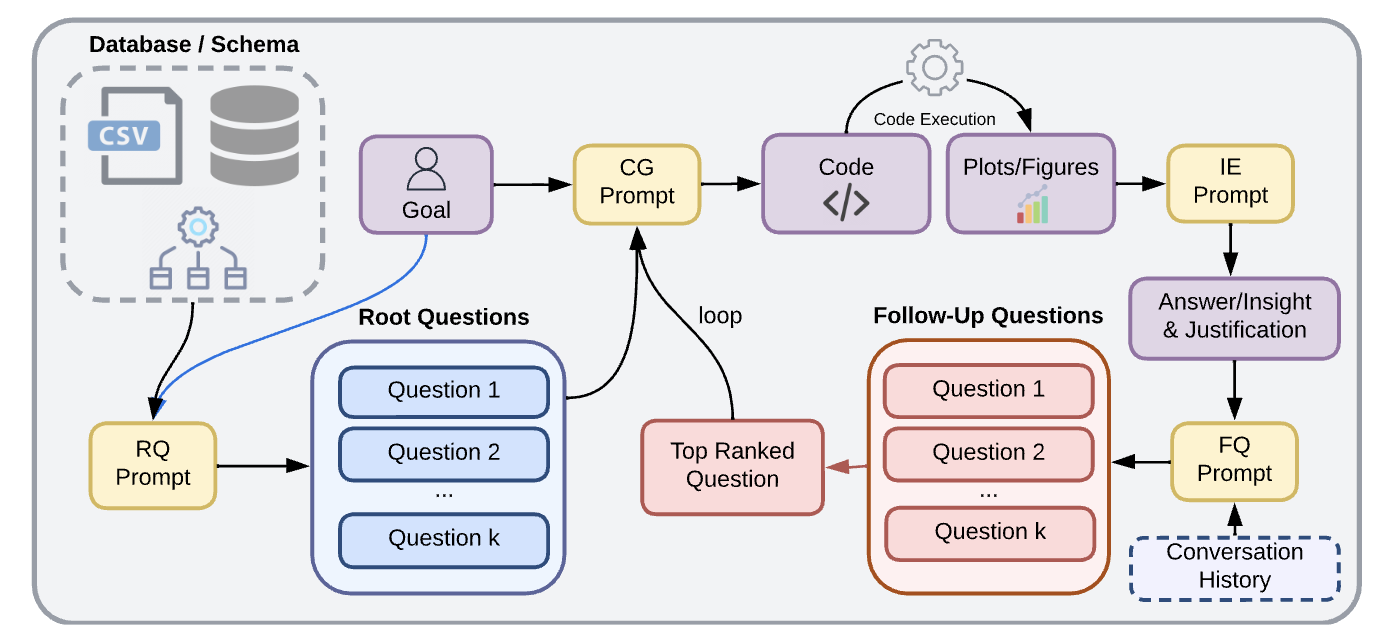
Our proposed baseline agent, AgentPoirot, follows a structured process for data analysis. It begins by utilizing a 'Question Generation (QG) Prompt' that takes as input the dataset schema and an overarching goal to generate k high-level questions. Then, it utilizes a 'Code Generation (CG) Prompt' to generate a plots answering the high-level questions. Once the plots are generated, AgentPoirot utilizes the "Insight Extraction (IE) Prompt" to derive insights from the generated plots along with a justification for generating the respective insights. Finally, it utilizes the "Follow-Up Question (FQ) Prompt" to generate additional questions, and then selects the most relevant one using the "Question Selection (QS) Prompt." This selected question is fed back into the CG prompt to initiate the cycle of insight generation again.